다익스트라(Dijkstra) 알고리즘
다익스트라 알고리즘은 다이나믹 프로그래밍을 활용한 대표적인 최단 경로 탐색 알고리즘이다. 인공위성 GPS 소프트웨어 등에서 가장 많이 사용되는 알고리즘이다.
다익스트라 알고리즘은 특정한 하나의 정점에서 다른 모든 정점으로 가는 최단 경로를 계산한다. 이때, 거리가 음수인 간선은 포함할 수 없다. 하지만, 현실 세계에서는 거리가 음수인 경로는 존재하지 않아서 다익스트라는 현실 세계에 적용하기 매우 적합한 알고리즘 중 하나이다.
- 기본적으로 그리디 알고리즘을 바탕으로 하고 있다. 거리를 기록하며 이미 최단 경로를 구한 곳은 다시 구할 필요가 없기 때문에 다이나믹 프로그래밍으로 보기도 한다.
- 항상 최단 경로를 찾고 탐욕적으로 선택한다. - 그리디
- 이미 계산된 경로를 저장후, 그를 활용해 중복된 하위 문제를 푼다. - DP
다익스트라 알고리즘이 다이나믹 프로그래밍인 이유는 “최단 거리가 여러 개의 최단 거리”로 이루어져 있기 때문이다. 즉, 하나의 최단 거리를 구할 때, 이전까지 구했던 최단 거리 정보를 그대로 사용한다는 것이다. 굳이 한 번 최단 거리를 구한 곳은 다시 구할 필요가 없기 때문이다. 이를 활용해 정점에서 정점까지 간선을 따라 이동할 때 최단 거리를 효율적으로 구할 수 있다.
다익스트라를 구현하기 위해 두 가지를 저장해야 한다.
- 해당 정점까지의 최단 거리를 저장
- 정점을 방문했는 지 저장
시작 정점으로부터 정점들의 최단 거리를 저장하는 배열과, 방문 여부를 저장하는 것이다.
같은 목적을 가진 알고리즘
- BFS
- 가중치가 없는 그래프. 시작점에서 큐에 인접노드를 넣어가며 방문하지 않은 노드들을 탐색하여 목적점에 도착하면 종료하는 탐색방식인데, 가중치가 있으면 돌아서 오는 가중치 합이 최단 경로가 될 수 있어 순수 BFS 탐색방식으로는 탐색할 수 없는 것이다. 하지만 BFS는 다익스트라 알고리즘의 기본 아이디어다. BFS + 우선순위 큐로 삽입된 정보 중 가장 최단 거리부터 꺼내 방문하는 방식이 다익스트라 알고리즘이다.
- 벨만-포드(Bellman-Ford)
- 음수 가중치가 포함되어도 최단 거리를 찾을 수 있다. 시간 복잡도가 다익스트라보다 느리다. 그 이유는 미방문 노드 중 가중치가 가장 짧은 노드를 선택해 뽑아오는 다익스트라와는 달리 각 정점들을 차례로 탐색하며 해당 정점의 간선들을 모두 탐색한다. 벨만-포드의 이러한 특성은 음수 가중치가 포함되어도 최단 거리를 찾을 수 있는 이유기도 하다. 또한 음수 사이클 유무를 판단 가능하다.
- 플로이드-워셜(Floyd-Warshall)
- 한 정점에서 다른 모든 정점까지의 최단 거리를 구하는 앞 방식들에 비해 플로이드-워셜은 모든 노드 간의 최단 거리를 구할 수 있다. 음수 가중치가 포함되어도 된다. 다만 3중 for문을 사용하기에(최악 O(n^3)), 문제의 범위를 잘 확인한 후 적용해야 한다.
프로세스
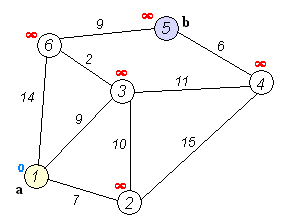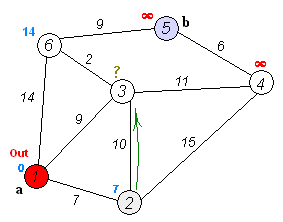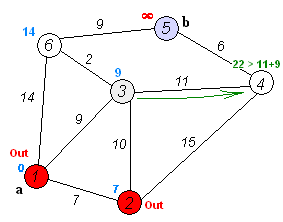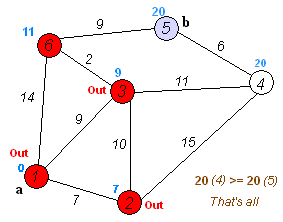
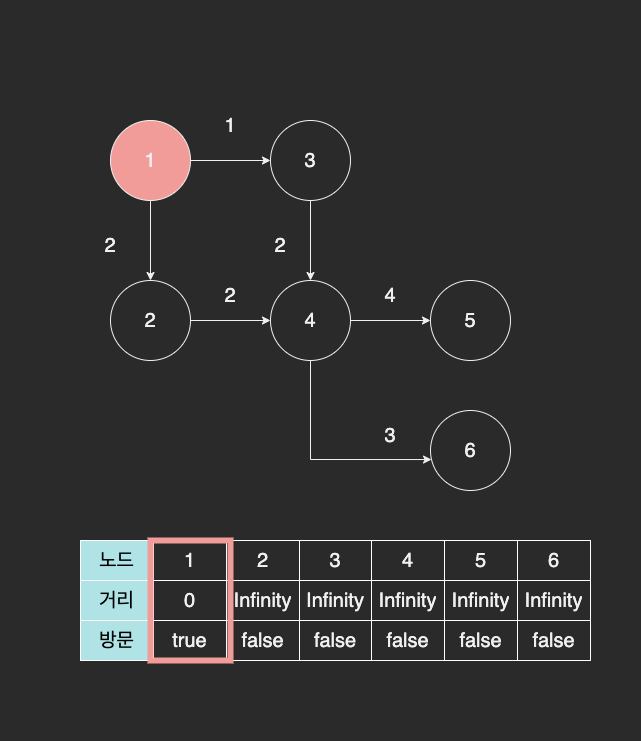
다음과 같이 1번 노드에서 각 노드까지 최단 거리를 구한다고 해보자.
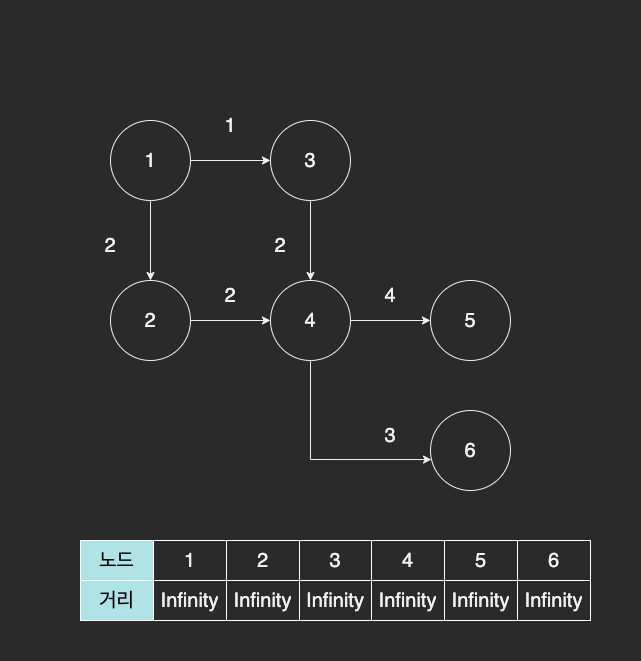
노드 간의 거리를 저장하는 테이블에는 무한대의 값을 저장해서 영원히 닿을 수 없다는 의미로 초기화 했다.
출발 노드는 1번 노드에서 시작한다. 1번 노드는 자기 스스로와 거리가 0 이기 때문에 먼저 0 으로 채워넣는다.
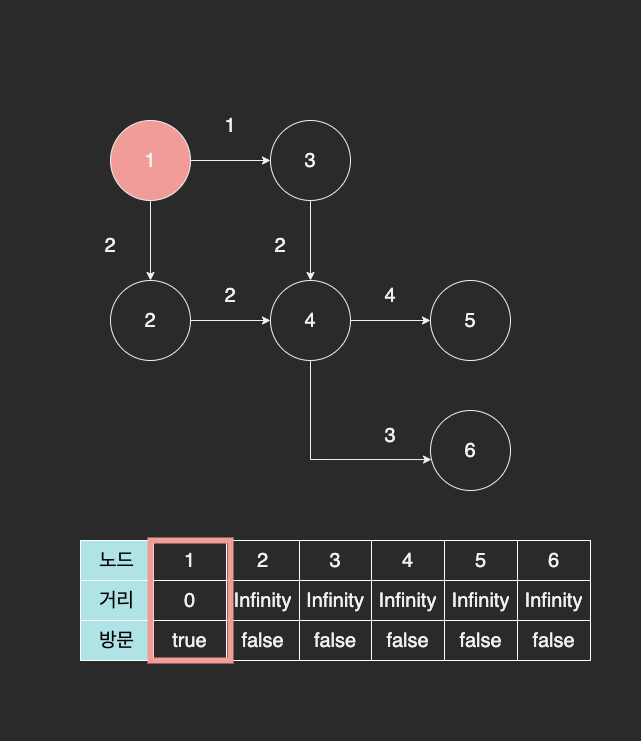
현재 1번 노드와 직접 연결된 노드는 2, 3번 노드이다. 각각의 노드까지 걸리는 거리를 다음과 같이 테이블에 저장한다.
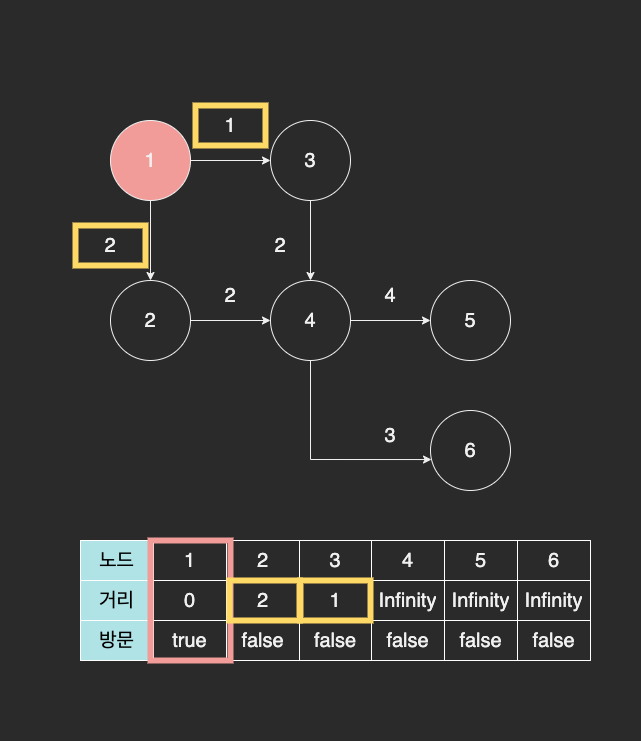
이제 다음에 방문할 수 있는 노드는 2번과 3번 노드이다. 이 중에서 거리 테이블 상에서 가장 작은 값을 가진 3번 노드를 방문한다.

3번 노드와 4번 노드의 거리는 2 인데, 거리 테이블의 4번 노드 자리에
- 1번 노드에서 3번 노드까지 이동한 거리
- 3번 노드에서 4번 노드까지 이동한 거리
를 더해서 저장한다. 즉, 1번 노드부터 누적해서 이동한 거리를 저장하는 것이다.
그 다음, 다시 거리 테이블에서 가장 작은 값을 가졌고, 방문하지 않은 노드인 2번 노드를 방문한다.
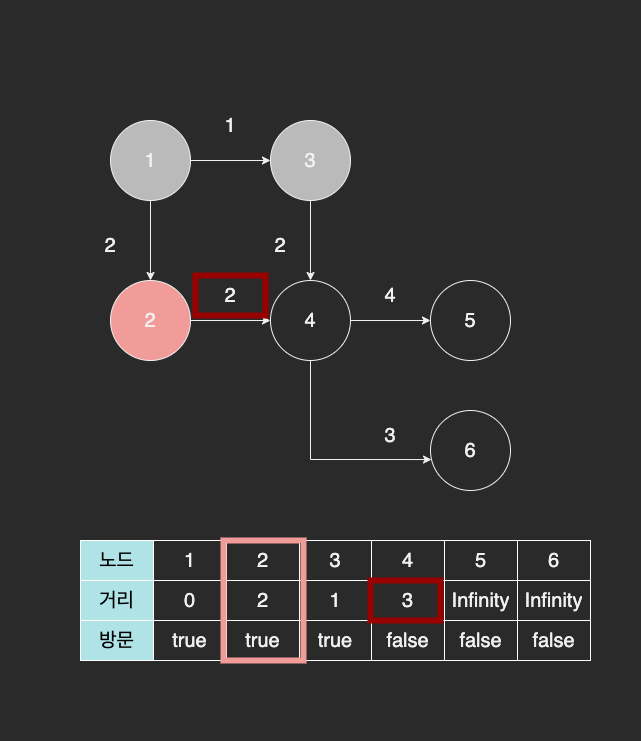
2번 노드와 연결된 4번 노드까지 거리는 2이고, 2번 노드를 거쳐 4번 노드로 간다면 총 거리는 4가 된다. 하지만, 3번 노드를 거쳐서 간 거리가 훨씬 짧기 때문에 거리 테이블에서는 값을 갱신하지 않는다.
마찬가지로 이전과 동일하게 거리 테이블 상에서 가장 작은 값을 가지면서, 방문하지 않은 4번 노드를 방문한다.
4번 노드부터 5번 노드와 6번 노드까지 거리를 기존에 이동한 거리와 더한 만큼 거리 테이블에 각각 저장한다.
다음으로, 거리 테이블 상에서 가장 작은 값을 가진 5번 노드를 방문한다.

하지만 더 이상 이동할 경로가 없으므로 마지막 남은 6번 노드를 방문한다.
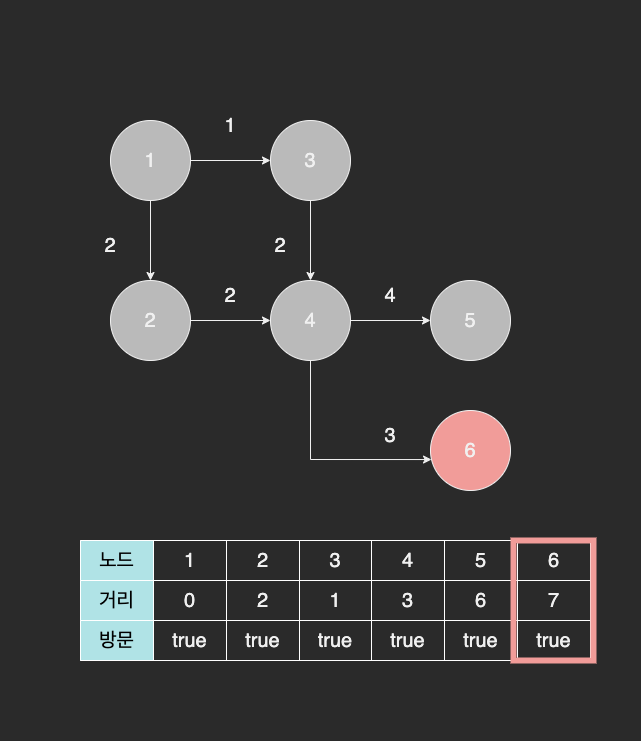
이제 모든 노드를 방문했기 때문에 탐색을 멈춘다.
최종적으로 거리 테이블에 저장된 값들은 1번 노드에서 각각의 노드까지 최단 거리가 저장된 것이다. 즉, 3번 노드를 거쳐 가는 경로가 가장 최단 경로가 되는 것이다.
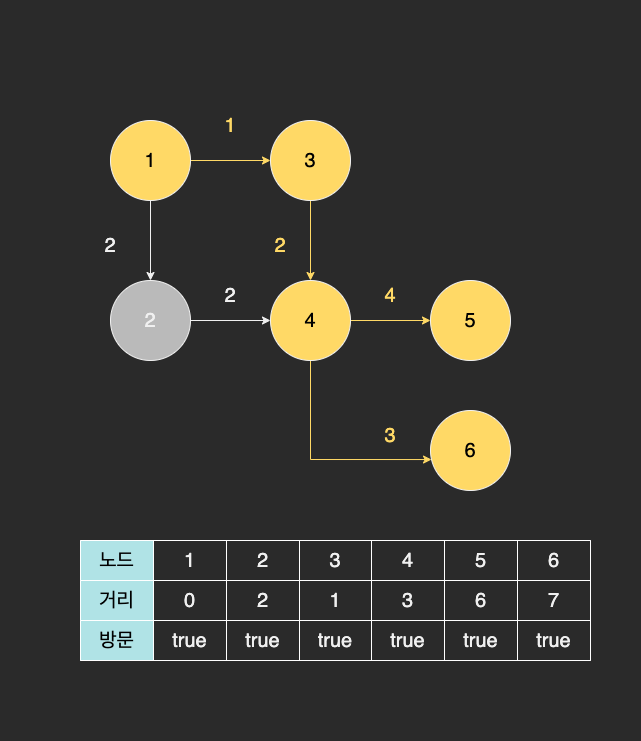
특징
다익스트라 알고리즘은 방문하지 않은 노드 중, 최단 거리인 노드를 선택하는 과정을 반복한다. 그리고 선택한 노드는 다시 한번 최단 거리를 갱신하는데, 이후에는 더 이상 작은 값으로 갱신되지 않는다.
한편, 다익스트라 알고리즘은 거리가 양수일 때만 사용할 수 있다.

위와 같이 2번 노드에서 4번 노드로 가는 거리를 모른다고 해보자. 그렇다면, 1번 노드에서 4번 노드로 가는 최단 경로가 3번 노드를 거쳐야 하는 것이라는 것을 보장할 수 있을까?
만약, 2번 노드에서 4번 노드까지 거리가 0 이거나 음수이면 2번 노드를 거치는 것이 최단 경로가 될 것이다. 그렇기 때문에 1번 노드에서 3번 노드를 거쳐가는 경로가 최단 거리라고 할 수 없는 것이다.
Ex)
다익스트라 알고리즘은 BFS 를 기반으로 구현할 수 있다.
세부적으로는 크게 2가지로 구현할 수 있는데, 거리 테이블을 매번 탐색하는 ‘순차 탐색’ 방식과 거리가 짧은 노드를 우선 탐색하는 ‘우선순위 큐’를 이용한 방식이 있다.

1. 순차 탐색
// 노드 간의 거리를 초기화
const graph = [
[Infinity, 1, Infinity, 2, Infinity],
[1, Infinity, 3, Infinity, 2],
[Infinity, 3, Infinity, Infinity, 1],
[2, Infinity, Infinity, Infinity, 2],
[Infinity, 2, 1, 2, Infinity],
];
// 방문 여부를 기록할 배열 생성
const visited = Array(N).fill(false);
// 1번 노드로부터 각 노드까지의 최단 거리를 저장한 배열 생성
const dist = visited.map((_, i) => graph[0][i]);
// 방문하지 않았으면서 거리 테이블에서 가장 작은 값을 가진 노드 탐색
const findSmallestNode = (visited, distance) => {
let minDist = Infinity;
let minIdx = 0;
for (let i = 0; i < distance.length; i++) {
if (visited[i]) continue;
if (distance[i] < minDist) {
minDist = distance[i];
minIdx = i;
}
}
return minIdx;
};
// 다익스트라 알고리즘 수행
const dijkstra = (graph, visited, dist) => {
// 1번 노드는 거리를 0으로 설정하고, 방문한 것으로 처리
distance[0] = 0;
visited[0] = true;
/*
현재 방문한 노드는 거리 테이블 상에서 가장 거리가 짧은 값을 가진 노드.
다음에 방문할 노드에 저장된 값이
"현재 방문한 노드까지 누적 이동 거리 + 다음 노드까지 거리"보다 크다면
"현재 방문한 노드까지 누적 이동 거리 + 다음 노드까지 거리"를 거리 테이블의 다음 방문할 노드에 저장
*/
for (let i = 0; i < distance.length; i++) {
const nodeIdx = findSmallestNode(visited, distance);
visited[nodeIdx] = true;
for (let j = 0; j < distance.length; j++) {
if (visited[j]) continue;
if (distance[j] > distance[nodeIdx] + graph[nodeIdx][j])
distance[j] = distance[nodeIdx] + graph[nodeIdx][j];
}
}
};순차 탐색 방식은 ‘방문하지 않은 노드 중 거리값이 가장 작은 노드’를 다음 탐색 노드로 선택한다. 그 노드를 찾는 방식은 거리 테이블의 앞에서부터 찾아내야 하기 때문에 시간 복잡도는 이 된다.
시간 복잡도를 줄이기 위해 을 보장하는 우선순위 큐를 사용한다.
다만, JavaScript 에서 우선순위 큐 자체를 구현하기 보다 우선순위 큐 개념을 이용해서 구현했다.
2. 우선순위 큐
그래프는 2차원 배열 안에 객체 형태로 to 목적지와 dist 거리를 저장했다.
// 0번 노드는 사용하지 않는 빈 노드이다.
// 이는 시작 노드를 1번으로 설정하기 위함이다.
const graph = [
[], // 사용X
[
{ to: 2, dist: 1 },
{ to: 4, dist: 2 },
],
[
{ to: 1, dist: 1 },
{ to: 3, dist: 3 },
{ to: 5, dist: 2 },
],
[
{ to: 2, dist: 3 },
{ to: 5, dist: 1 },
],
[
{ to: 1, dist: 2 },
{ to: 5, dist: 2 },
],
[
{ to: 2, dist: 2 },
{ to: 3, dist: 1 },
{ to: 4, dist: 2 },
],
];
// 1번 노드와 각 노드까지 최단 경로를 저장하는 배열 생성
const dist = Array(graph.length).fill(Infinity);
// 큐 생성 및 1번 노드에 대한 정보 저장
const queue = [{ to: 1, dist: 0 }];
// 1번 노드의 거리는 0 으로 설정
dist[1] = 0;
// 큐가 빌 때까지 반복
while (queue.length) {
// 큐에서 방문할 노드 꺼내기
const { to } = queue.pop();
// 방문한 노드까지 이동한 거리 + 다음 방문 노드까지 거리를
// 기존에 저장된 값과 비교해서 갱신
graph[to].forEach((next) => {
const acc = dist[to] + next.dist;
if (dist[next.to] > acc) {
dist[next.to] = acc;
// 최단 경로가 되는 노드는 큐에 추가
queue.push(next);
}
});
}'[Basic] Data > Algorithm' 카테고리의 다른 글
| [Algorithm] 탐욕 알고리즘 (Greedy Algorithm) (0) | 2023.03.13 |
|---|---|
| [Algorithm] 비트마스크 (BitMask) (1) | 2023.03.13 |
| [Algorithm] 동적 계획법 (DP. Dynamic Programming) (0) | 2023.03.13 |
| [Algorithm] 최소 공통 조상 (LCA. Lowest Common Ancestor) (0) | 2023.03.13 |
| [Algorithm] 최장 증가 수열 (LIS. Longest Increasing Sequence) (0) | 2023.03.13 |



댓글